SSTable и LSM-деревья. Как хранить ключ-значение на диске?
Содержание
Table of Contents
Хэш-таблица
Что первое приходит в голову при упоминании Ключ-значения хранилища? Думаю у большинства в голове всплывает Словарь или Хэш-таблица зависит от вашего языка. Итак, первой имплементацией будет Хэш-индекс. Он хорошо вписывается в память. Но что на счет постоянного хранилища? Давай-те представим открытый файл в который мы пишем в конец. В этой концепции мы можем представить значения в Хэш-таблице как смещение в этом файле когда мы вставляем или обновляем данные.
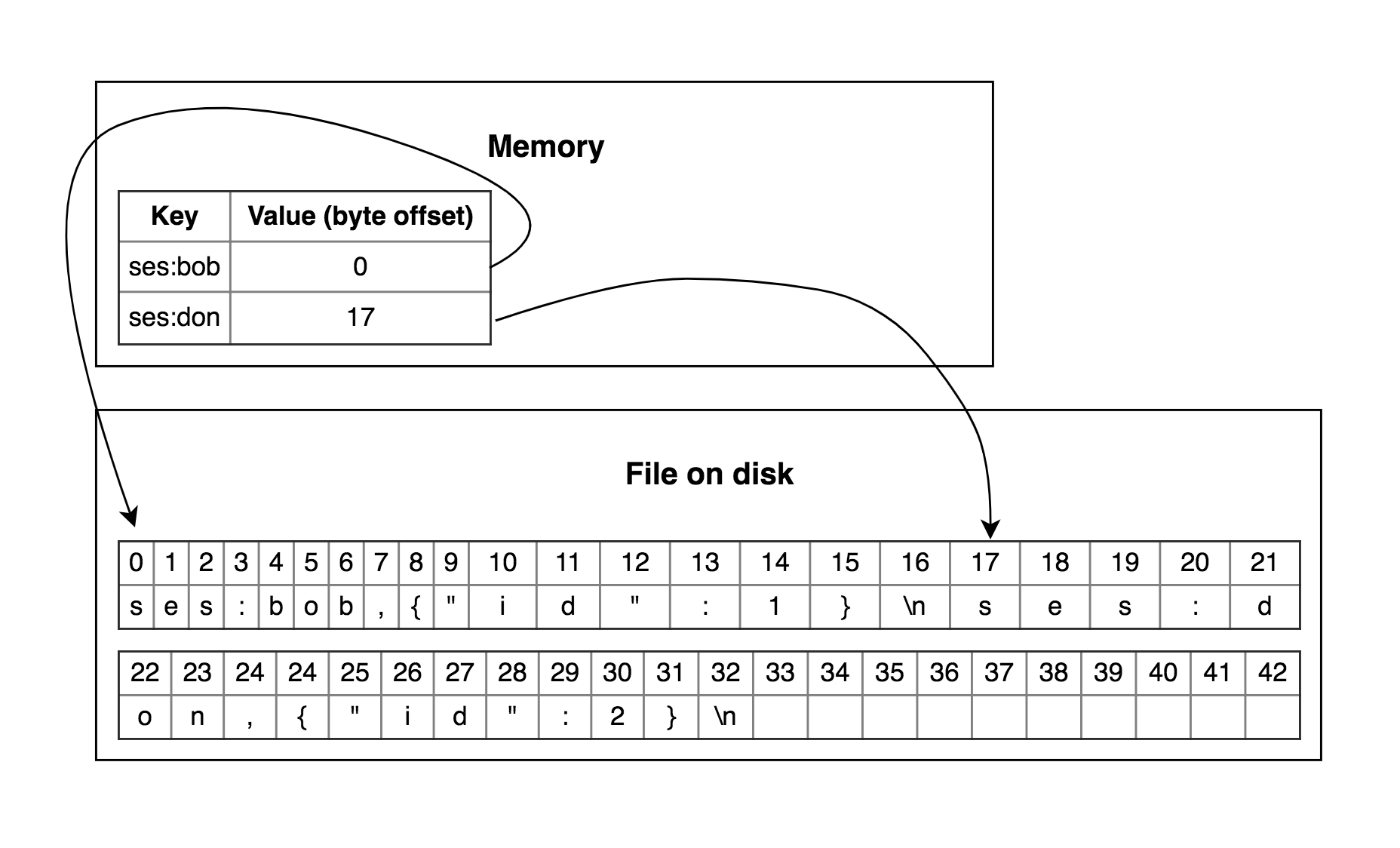
Но в таком случае мы можем быстро израсходовать наше место на диске если будет только дописывать значения в конец файла при вставках и изменении. В этом случа мы можем разделить наш файл на сегменты. При достижении определенного размера файлы, мы его закрываем, открываем новый. В фоне мы будем запускать процесс, который будет обрабатывать старые сегменты, удалять дублирующие данные и оставлять только самые свежие.
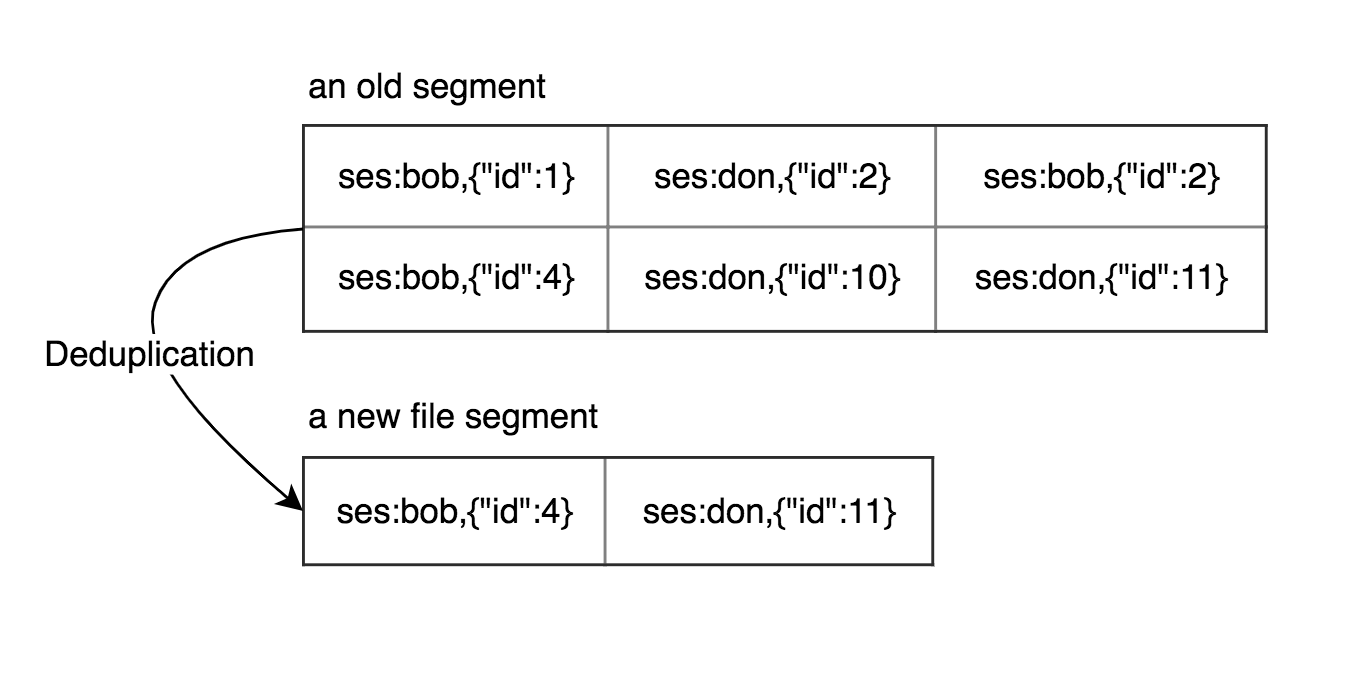
Мы решили проблему с дублирующимися данными, но осталась проблема дублирования значений в разных сегментах. В таком случае мы можем объеденять старые сегменты.
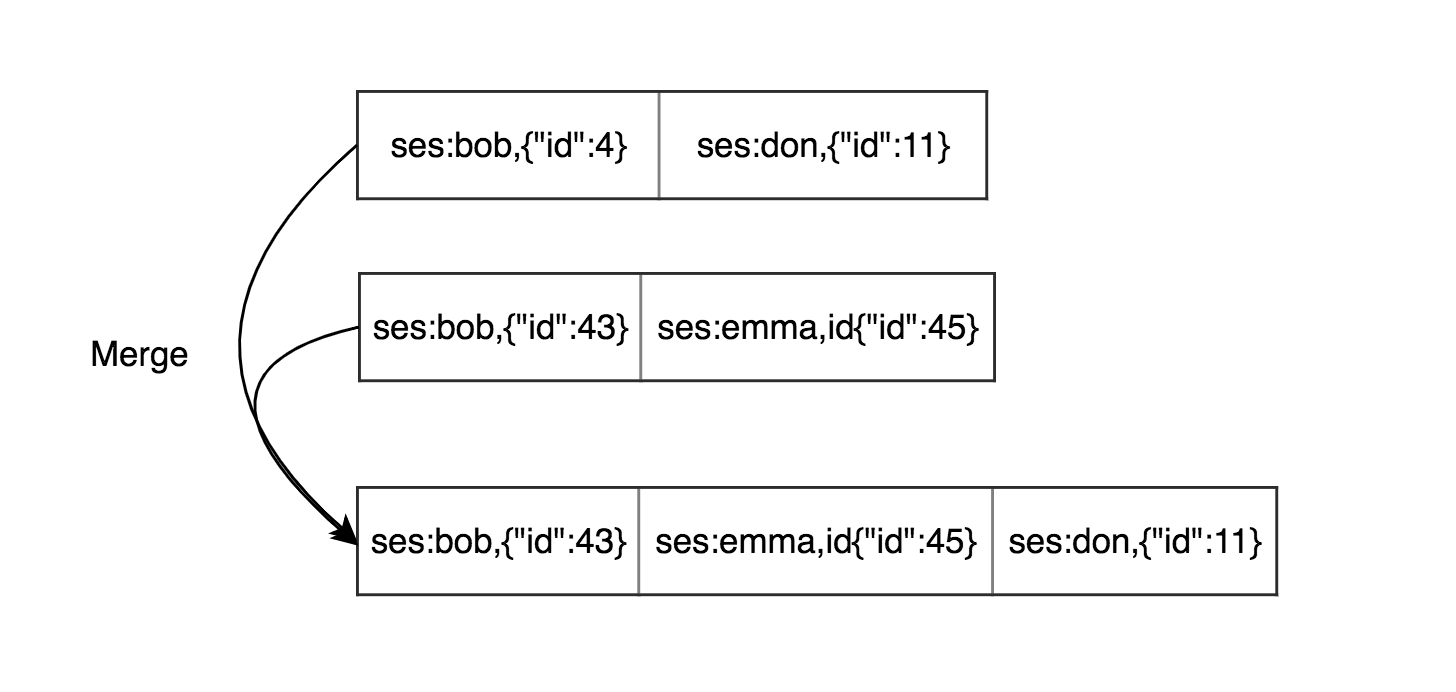
В таком случае, у нас есть хэш-таблица в памяти для каждого сегмента и нам нужно держать оптимальное количество активных сегментов, чтобы не обращаться к большому кол-ву хэш-таблиц. Режим записи в конец файла может показаться источительным по сравнению с обновленим записи напрямую на диске, но это ражим имеет ряд приемуществ:
- Последовательная запись на диск намного быстрее, чем произвольная.
- Многопоточность и экстренное востановление намного проще если сегменты не изменяемы. Например, не нужно беспокоится о частях сегмента которые частично записаны в случае падения.
- Слияние позволяет избежать фрагментирования данных с течением времени.
Этот метод так-же имеет свои ограничения:
- Нужно имет ввиду что хэщ-таблица всегда должна помещатся в памяти. Иметь большое количество ключей - плохая идея.
- Запросы по диапазонам ключей не возможны.
Давай-те перейдем к основной идеи, для чего эта статья и писалась.
SSTables и LSM-деревья
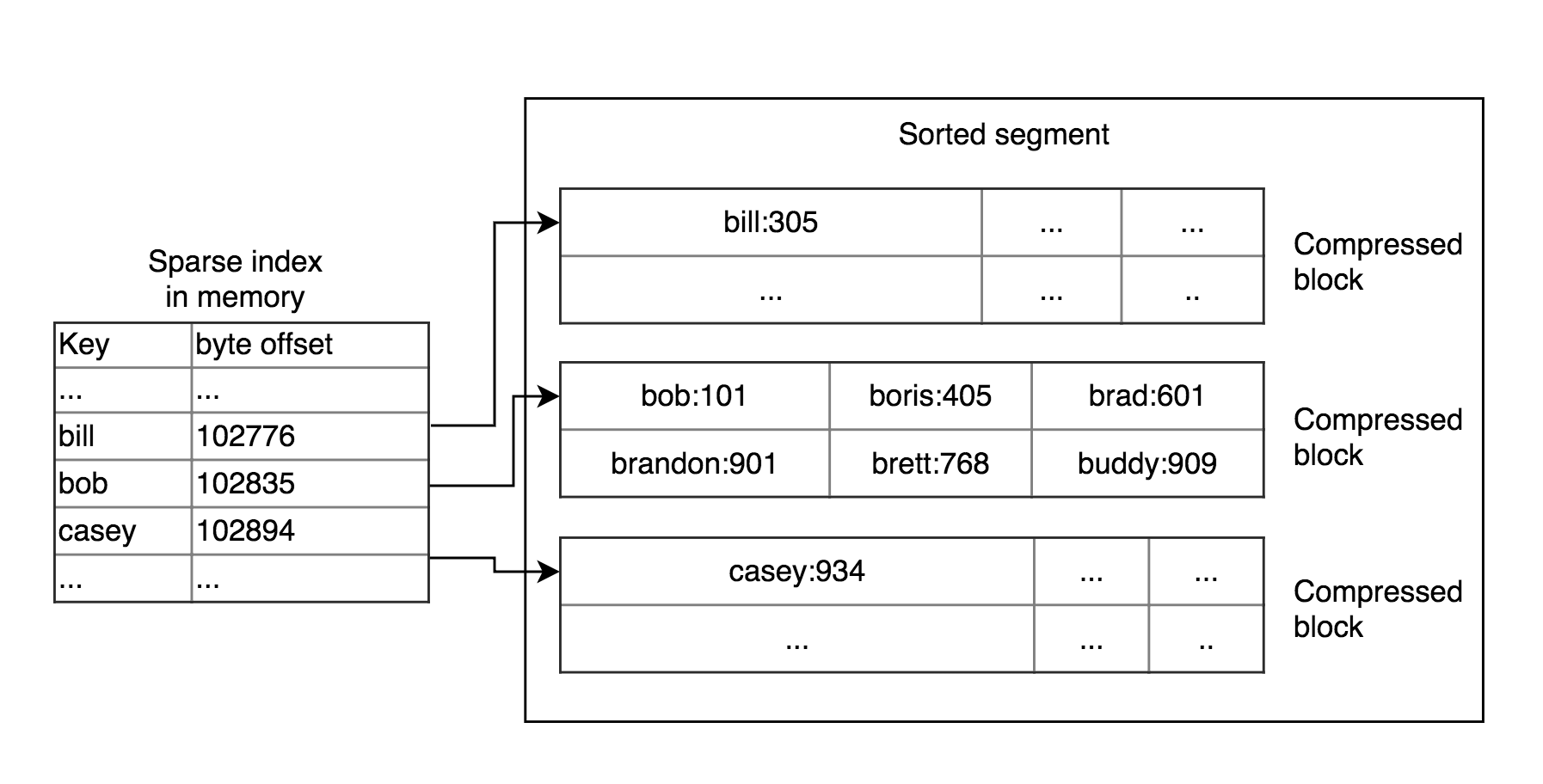
Sorted String Tables (SSTables) хранит данные упорядоченые по ключу и ключ встречается только единожды. Итак, если мы имеет отсортированные данные на диске по ключу, мы имеем некоторые приемущества:
- Слияние сегментов проще. Мы можем использовать сортировку слиянием читая несколько сегментов с начала и слиять их. Имейте ввиду в процессе слияния что ключи из более свежих сегментов являются релевантными.
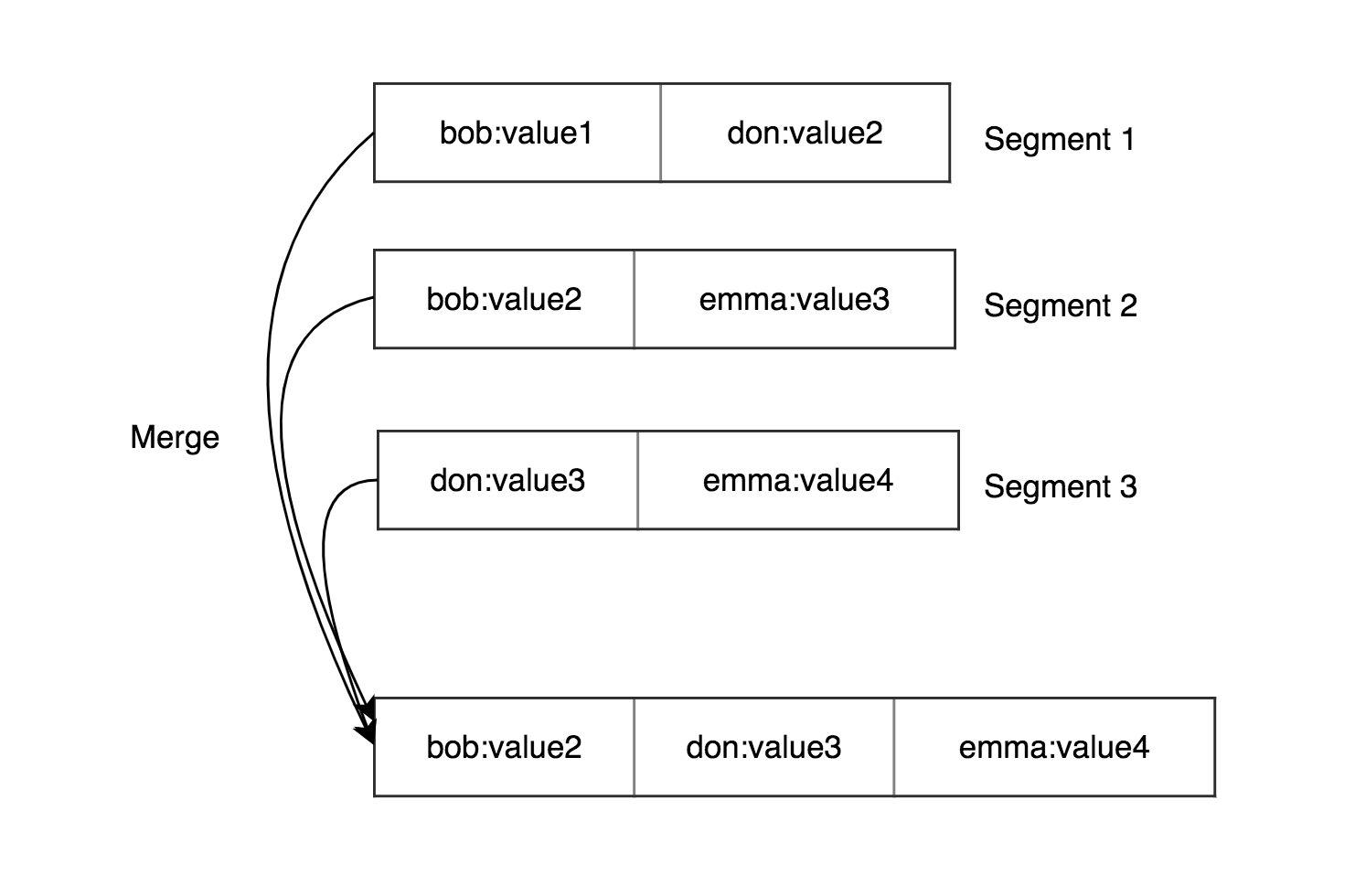
- Нам не нужно хранить все ключи в памяти. Мы можем хранить только разряженный индекс, например на несколько килобайт, который можно обойти очень быстро.
- Мы можем сжимать блоки ключей потому что мы все равно сканируем все ключи в блоке. В таком случае мы сохраняем место на диске и I/O
- We don’t need to keep all keys in memory. We can keep a sparse index for example for every few kilobytes because it can be scanned very quickly.
- We can compress blocks of keys because we scan the full range of keys in this block anyway. In this case, we save disk space and пропускную способность I/O.

Реализация
Для поддержки индекса мы можем использовать любое самобалансирующиеся дерево (красно-черное или АВЛ-дерево)
- Все вставки идут в самобалансирующиеся дерево которое иногда называется memtable
- Когда memtable вырастает до определенного момента, мы создаем новое дерево для последующих вставок и сохраняем предыдущее на диск как новый сортированный сегмент
- Чтения пытаются найти ключ в memtalbe в первую очередь, затем в сегментах на диске.
- Процесс слияния запускается время от времени в фоновом режиме.
- нам нужно хранить отдельный лог-файл для последних записей на диске для востановления. Когда база данных падает, мы должны восстановить memtable из этого лога.
Заключение
LSM-дерево способно выстоять высокую скорость записи из-за низкого усиления записи. Другим достоинством является компактная запись. Сжатие и дефрагментация помогает нам в этом. Из минусов, процесс слияния может повлиять на скорость ответа. LSM-Деревья используются в таких базах как Casandra, HBase, Google Bigtable, InfluxDB, и т.д.
Источники: