SSTable and LSM-trees. How to store Key-Value storage on the disk?
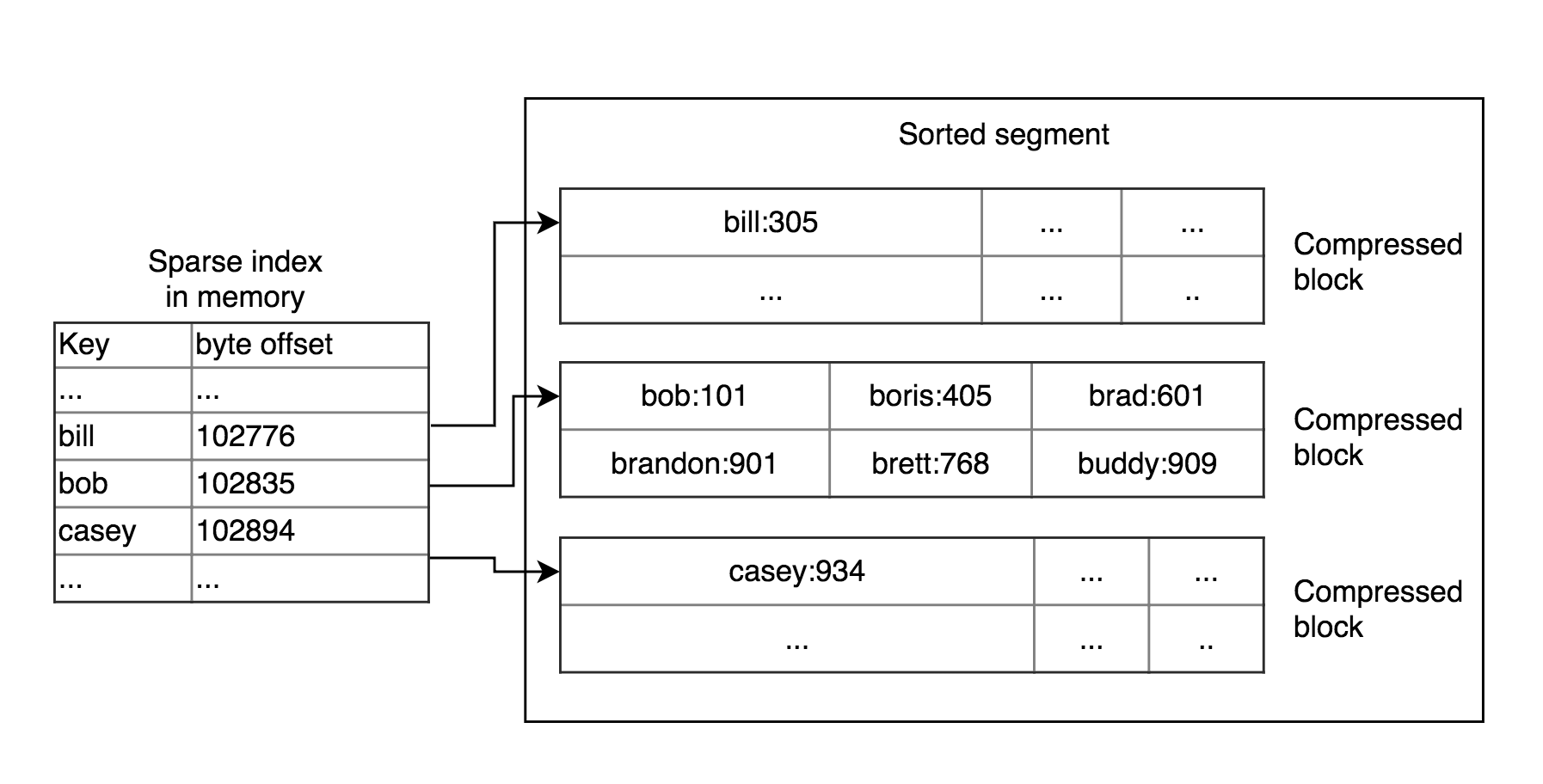
Table Of Content
Table of Contents
Hash Table
What is Key-Value storage? First, you could think about Dictionary and Hash-Map depends what is your favorite programming language. So our first implementation will be Hash-index. Hash-Map good fit into memory. What about data storage? Let’s say our storage is an opened file where we can write in append mode. Then we can use Hash-Map values as an offset in the file when we insert or update a new value.
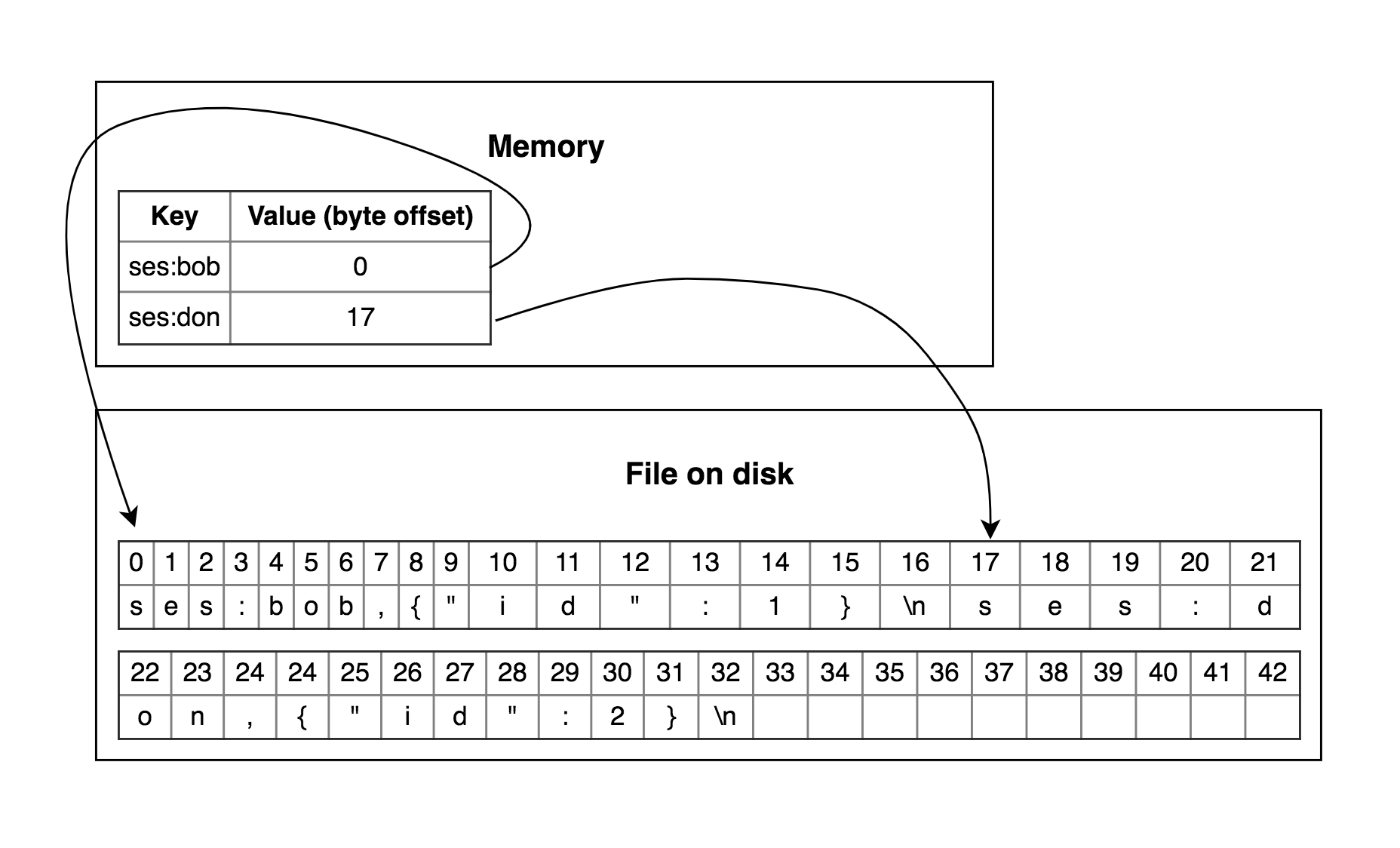
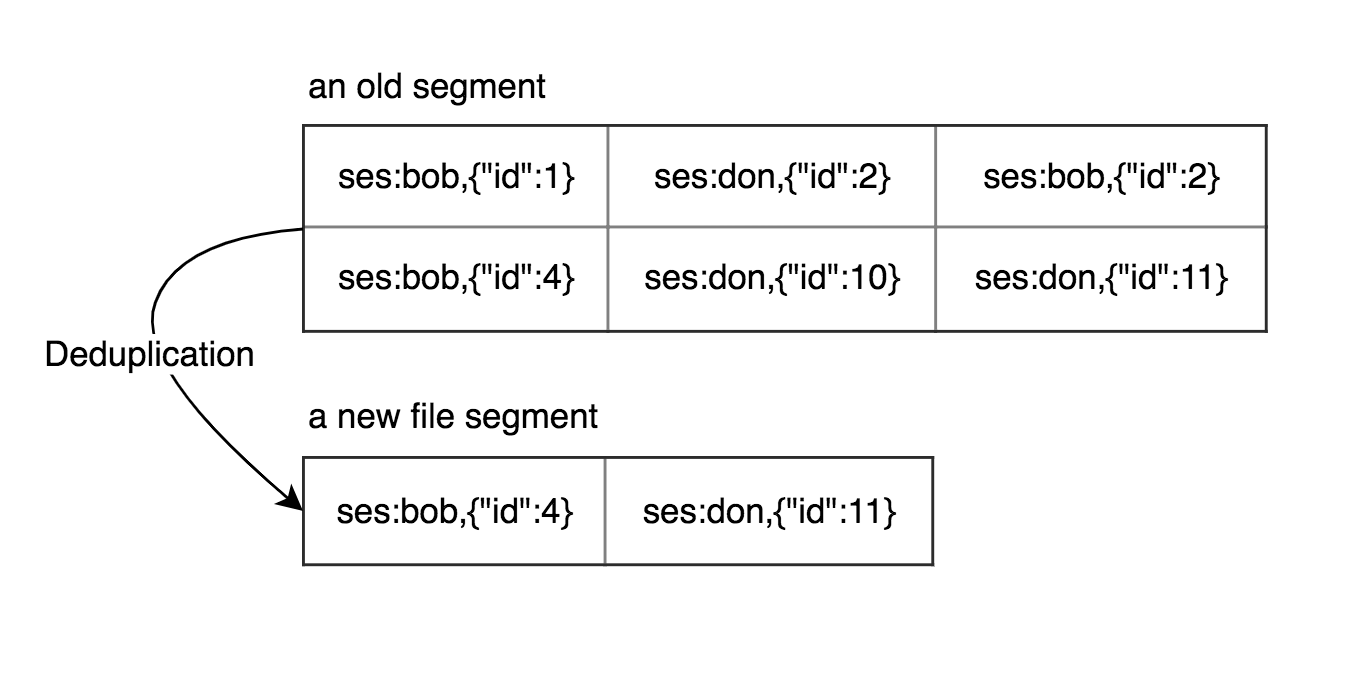
As described so far, we will easily spend whole our storage if we continue to append new information to the end of the file. In this case, we can split our storage into segments and process old segments to drop old keys and keep only recent keys. Let’s choose a segment size. Our write process closes the current segment and opens a new one when it reaches the size of the segment and another process could deduplicate keys from segments which were closed. After processing we can drop the old segment. Therefore we save our disk space.
We solve the problem with duplication keys in one segment but keys might be duplicated in different segments. We could merge 2 segments together.
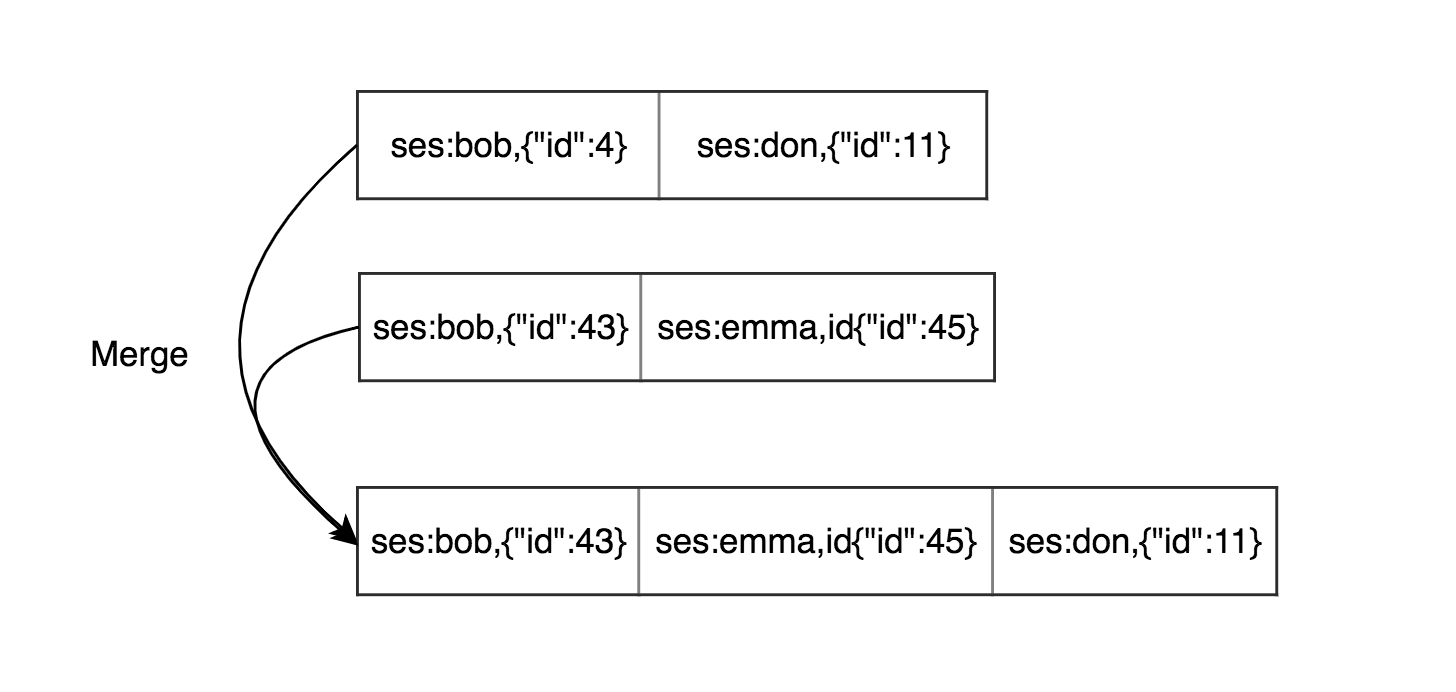
In this case, we have an in-memory hash map for each file segment then need to find the optimal amount of current active file segments to do not look up in many hash-tables. Append mode might be seen wasteful at first glance comparing updating each record directly but there are some advantages:
- Sequential writes are much faster than random writes.
- Concurrency and crash recovering are much simpler when segments are immutable. For example, you don’t need to worry when some part of your segment has been partly written in case of a crash.
- Merging allows avid case when your data are fragmented over time.
However, this approach has limitations:
- You have to fit your hash-tables into memory. Having a lot of keys is a bad idea.
- Range queries are not possible.
Let’s take a look at the main approach in this article.
SSTables and LSM-Trees
Sorted String Tables (SSTables) keep data sorted by key and keys appears only once. So if we have sorted data by key on a disk then we have advantages:
- Merging segments is simpler. We can use mergesort approach reading several segments from the beginning and merge them. Keep in mind while merging that we have more recent keys in one segments and old in another.
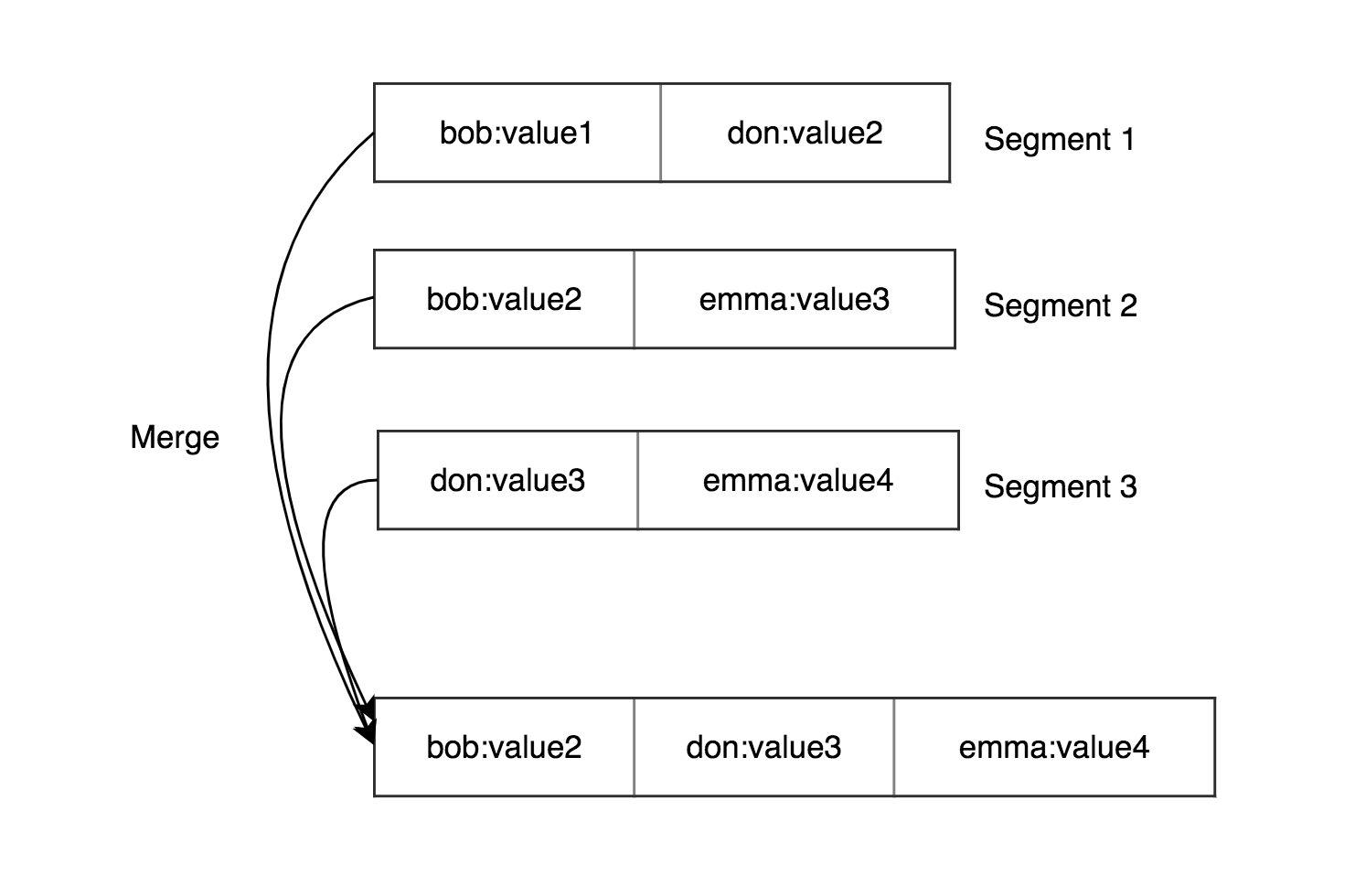
- We don’t need to keep all keys in memory. We can keep a sparse index for example for every few kilobytes because it can be scanned very quickly.
- We can compress blocks of keys because we scan the full range of keys in this block anyway. In this case, we save disk space and I/O bandwidth.

Implementation
For maintaining an index we can use any balance tree structure (red-black or AVL)
- All inserts go to an in-memory self-balance tree which called sometimes memtable
- When memtable grows more than some threshold we create a new one for next writes and store previous memtable on disk as a new sorted segment.
- Reads try to find a key in memtable firstly then in the next-older segment, etc.
- Merging process is executed in the background from time to time.
- We need to keep a separate log of recent writes on disk for recovering. When the database goes down we have to recover memtable from the log.
Summary
LSM-trees are able to sustain high write throughput because of low write amplification. Another advantage is that data are written more compact. Compressing and defragmentation help us with it. Talking about downsides, merging process can affect response time. LSM-Trees are used by Casandra, HBase, Google Bigtable, InfluxDB, etc.
Sources: