Site Reliability Engineering: Measuring and Managing Reliability (part 1)

Table Of Content
Table of Contents
DevOps vs SRE
The definition of SRE (Site Reliability Engineering) sounds like DevOps, but if we consider DevOps as a philosophy, then SRE is a concrete the implementation of this philosophy.
DevOps is broken into 5 key areas:
- Reduce Organization Silos
- Accept Failure as Normal
- Implement Gradual Change
- Leverage Tooling and Automation
- Measure Everything
Let’s imagine that these pillars are an interface for a class. Then implementation of SRE are:
- Reduce Organization Silos
- Share ownership with developers to create shared responsibility
- SREs use the same tools that developers use, and vice versa
- Accept Failure as Normal
- Blameless postmortems
- Error budget. How much the system is allowed to go out of spec.
- Implement Gradual Change
- To roll out features on small about of people by reducing the cost of failure
- Leverage Tooling and Automation
- Automate manual work
- Measure Everything
- To measure how much toil we have
- Measuring the reliability and health of the system

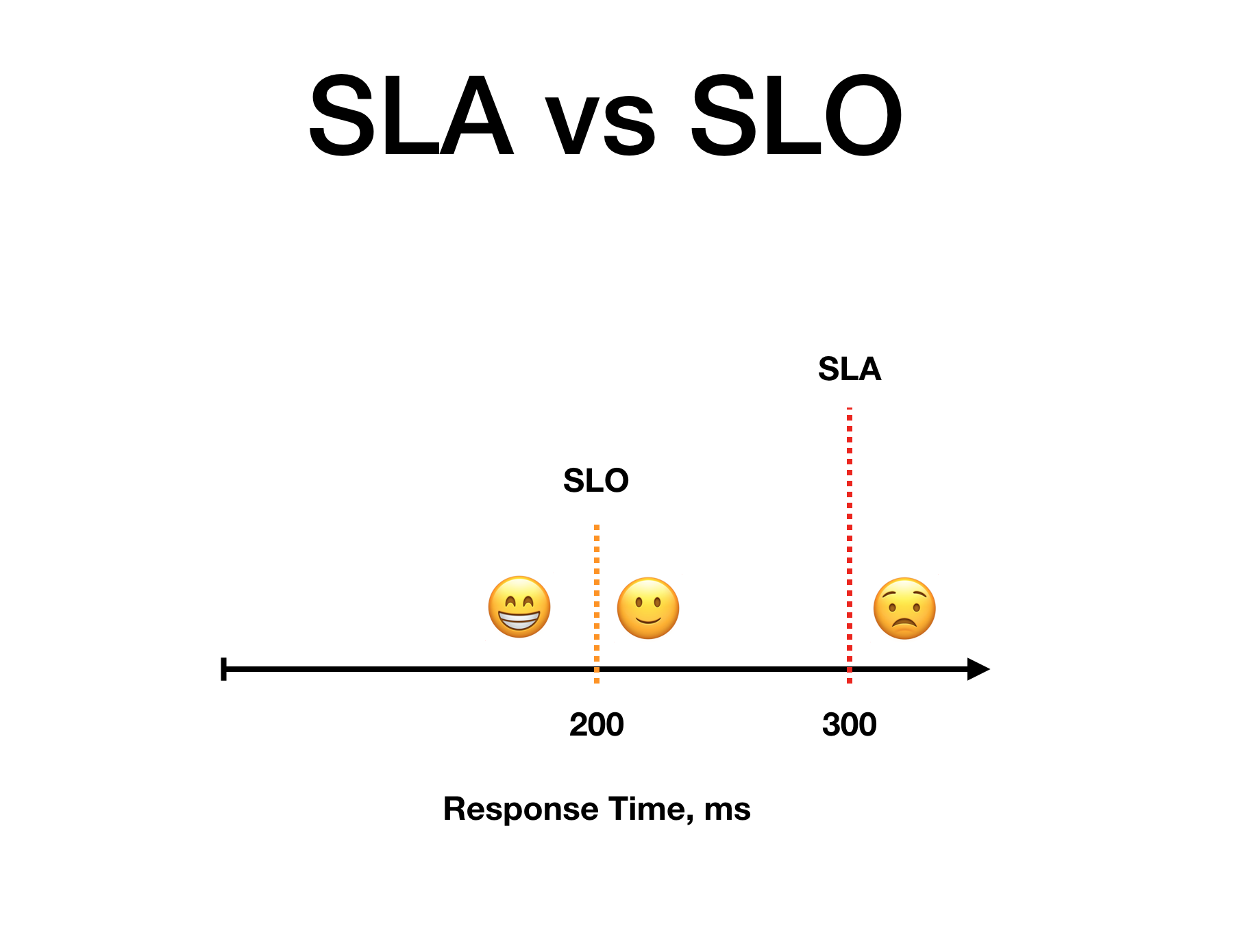
SLO & SLA
SLO (Service Level Objectives) - targets which allow for a company support a specific level of reliability to balance between delivering new features and support reliability. For the most development organization is most important to build new features as fast as possible. On the other hand with that approach, we reduce the service’s reliability consequently it decreases users’ experience. Another extreme case is to maintain reliability as much as possible. Then we don’t have features in this case. So SLOs tell when reliability is enough to keep features delivering in good pace and keep reliable your system for customers.
SLA (Service Level Agreements) - agreements with your customers about reliability which you will be fined after a violation.
SLO is a good metric of happy customers. When you breach your SLO is better to start reducing it to avoid reaching SLA when you will have consequences.
SLI (Service Level Indicators) - reliability measurements. It uses for specifying you SLO and SLA metrics (i.e. API response time, latency, error rate etc.).
Error Budget
When we agreed our SLO. Let’s say we have 99.9% uptime as our SLO. 0.1% is 40.32 minutes of downtime (28 days * 24 hours * 60 minutes * 0.1%) which is Error Budget. Error budget tells how unreliable your a service is going to be. You can spend this budget as you want (updating a software, releasing new features, for hardware failure etc.)
What to improve?
 Take a look at the formula:
Take a look at the formula:
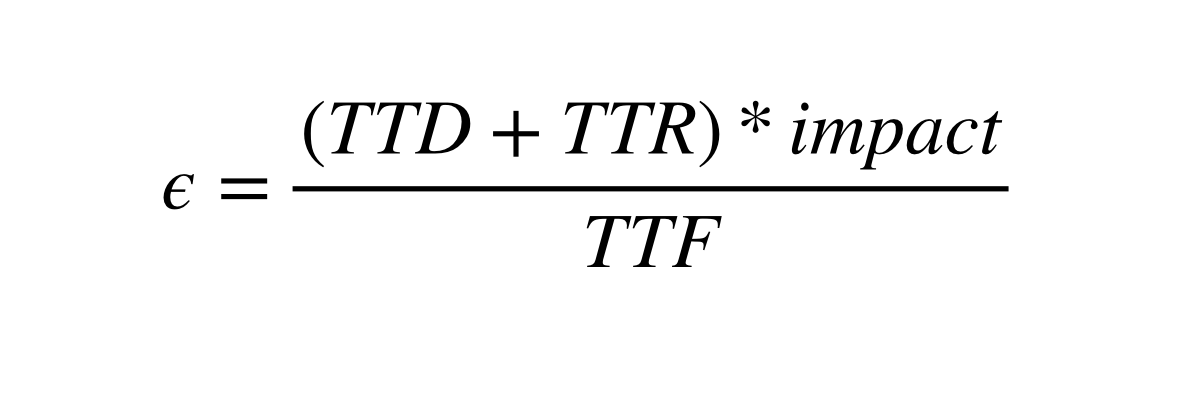
To improve reliability we can optimize any variable in the formula:
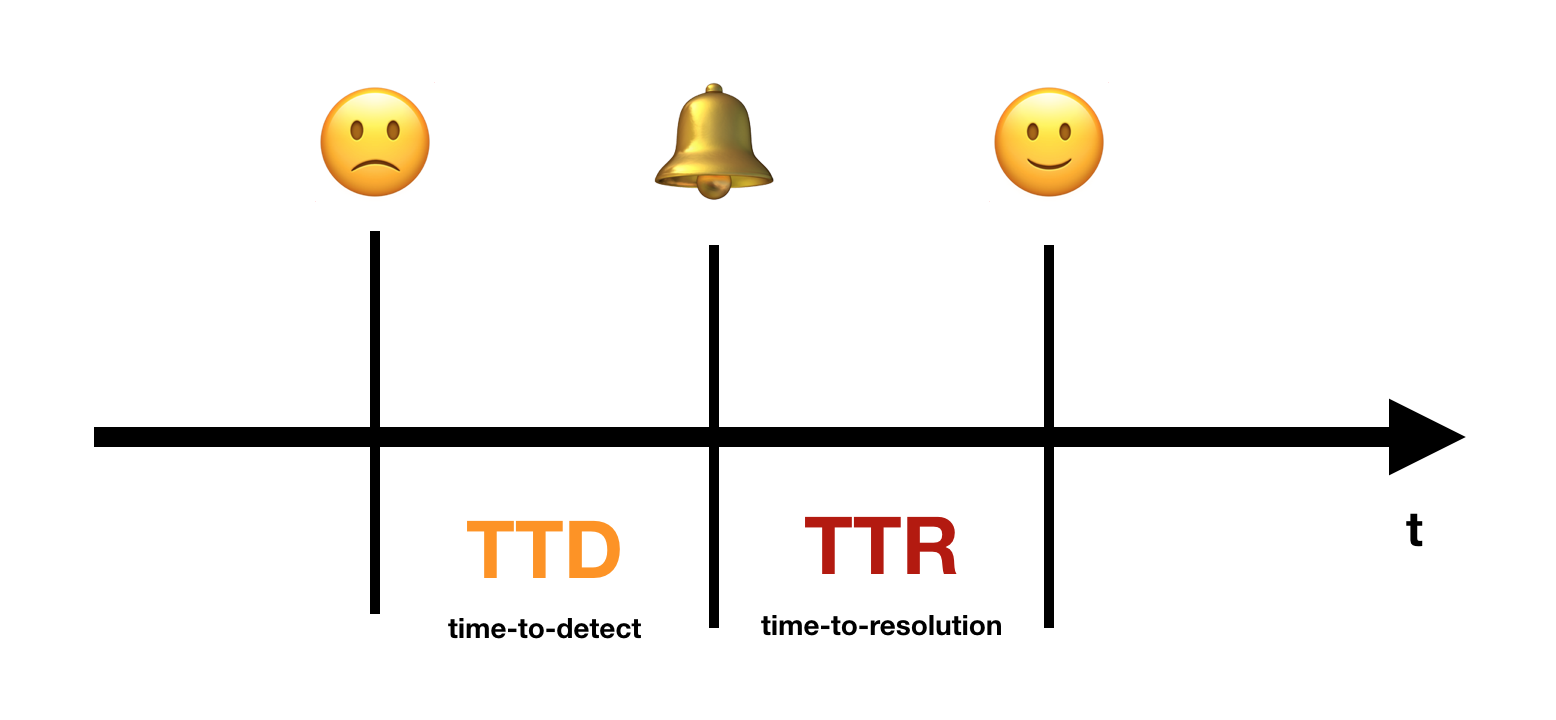
TTD (time-to-detect)
- good monitoring system
- automated alerting
TTR (time-to-resolve)
- developing a playbook
- easy to read an application log
- redirecting traffic from the failed zone
Impact
- roll out features gradually
TTF (time-to-failure)
- automatically direct traffic away from failure zones
There are additional approaches to improve reliability apart of formula variables.
- Reports on uneven error budget spend. Find cases where the error budget not evenly distributed and focus extra efforts in these regions.
- Standardize infrastructure. Some services wouldn’t work in diffident infrastructure. So it’s good to keep it similar.
- Consult on system design. It can catch reliability design issues early, which is often much cheaper than fixing them after the code has been written.
- Build safe release and rollbacks. Developing an automated release/rollback system decrease human errors when it really needs.
- Author postmortems. It can highlight what those bugs are and create action items to get them fixed.
- Use phased rollouts. You can release to production gradually and decrease possible impact on target users.
Summary
We know how to define problem space (SLOs and SLIs), can make your system is reliable enough, but no more. Error budgets are our trade-off between reliability and development velocity. SLO can be and must be aligned during the service lifetime. The relationship has to be strong to make this work.